Big Data-Future Has Arrived
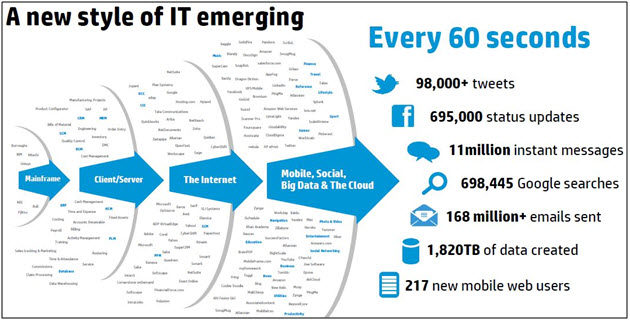
Due to arrival of new technologies and social networking sites, the amount of data produced is growing rapidly every year. By 2003, the amount of data produced was 5 million gigabytes. The same amount of data was produced every 10 minutes in 2011 and the amount is still increasing on a large scale.
Big Data is a collection of large data sets which can not be processed using a traditional approach. It requires various tools, techniques and frameworks to process the huge amount of data.
Less amount of data produced can be managed using the traditional approach of data handling. Here data will be stored in RDBMS(Relational Database Management System) like Oracle Database, MS SQL Server, MySQL or DB2.
This traditional approach of manipulating data can be useful with a smaller volume of data but dealing with large volume of data is painful. Minimum size of Big Data starts with at least 1 TB.It is about a TB or ZB (Zettabytes) of file.
From 1975-80’s use of RDBMS-Fixed schema,Fixed rows & Tables were there and it was carried out till 2000,then Facebook, Linkedin, Twitter started coming into picture. Earlier the information stored was UNSTRUCTURED.
UNSTRUCTURED data comprises of different format of files such as:
Audio files,video files,posts,images etc).In Year 2004-05,the data started increasing and it is when the amount of unstructured data increased & is still growing.
The 4 V’S of Big Data By IBM
- Volume: Large Volume Of Data
- Variety: Different formats(Audio,Video,Images,Posts,etc)
- Velocity: Speed of Data Processing.
- Varacity: To check that the Data is Genuine.
The traditional approach of data processing works on a portion/sample of data but Big Data works on the whole of any Data(collection of datasets).
Verticals that come under the roof of Big-Data
- Stock Exchange:
Data produced in stock exchange are huge enough to be handled by the traditional approach of Data handling(RDBMS).Here Buy/Sell decisions are made on share of different companies,Thus producing a big stack of data.Here Big-Data Techniques and tools can be used to overcome the disastorous data.
- Social Media:
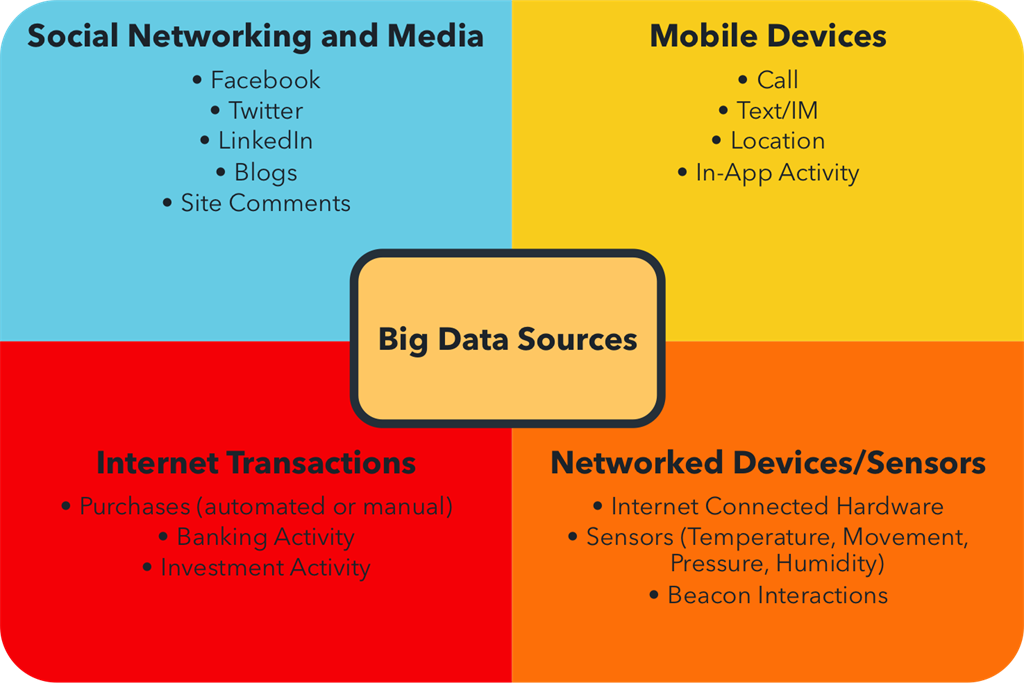
Due to the emergence of various social media applications/sites, the production of data is increasing day by day. Pictures/Images, and posts are being updated on a daily basis. Daily 500 TBs of data is updated on Facebook. Here Big-Data techniques are used to manage and manipulate this enormous data.
- Transport:
The transport data used in automobile industries is also very large to be handled traditionally. Transport Data includes Model, Capacity, Distance and availability of vehicles.
- Healthcare:
Big Data has helped improve Healthcare by providing personalized medicines, automated external and internal reporting of patient data, and standardized patient registries.
As you know that Tradititional Approach to process data is helpful for limited volume of data,but when we deal with Big-Data then tis traditional approach is of no use.
Google’s Solution for Big Data
Google solved the problem of huge data using an algorithm called MapReduce.
This algorithm divides the task into small parts and assigns those tasks to many computers connected over the network and collects the results to form the final result dataset.
Doug Cutting,Mike Cafarella and team took the Google’s Solution and started an open-source project named HADOOP in 2005 and Doug named it after his son’s toy elephant.
Hadoop runs applications using Map-Reduce Algorithm. Here the data is run parallel on different CPU nodes.At the beginning Yahoo & Doug was working on Hadoop Implementation and Google was working on its White Papers. After implementing they donated it to APACHE and then it came to be known as Apache Open Source Framework.
Hadoop is written in JAVA. Now APACHE Hadoop is the registered trademark of the Apache Software Foundation. Hadoop is a framework which will help you to save the file and do analytics on the top of it.It saves the file in Distributed File System(DFS).
Big Data is about TB and ZB of File.So we can get problem in opening and saving of file using Traditional Approach. Thereafter Hadoop is a framework which will help you to save the file and do analytics on the top of it. Big data usually includes data sets with sizes beyond the ability of commonly used software tools to capture, manage, and process data.
Hadoop is built on LINUX environment.
Conclusion
Here we have seen the insight of Big Data, its emergence and some of the applications where Big Data can be useful.We will learn some techniques used to resolve the problem of Big Data in the next lesson. Nowadays an immense need has arisen to control the Data mountain that is growing rapidly.